プログラムのパフォーマンスを向上させるために「キャッシュ」は欠かせません。特に、よく使われるデータを効率よく保存する LRUキャッシュ(Least Recently Used Cache)は、多くの場面で活用されています。この記事では、LRUキャッシュの基本から実装、応用例までわかりやすく解説します。
LRUキャッシュとは?
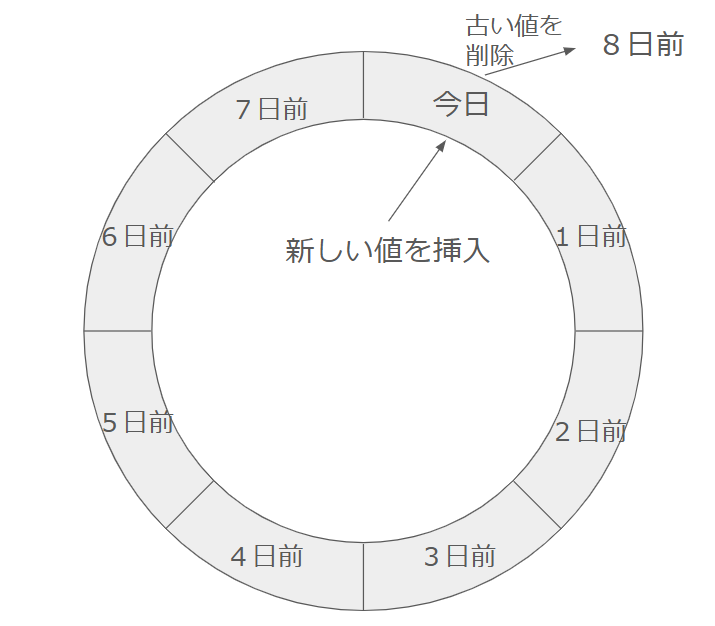
LRUは「Least Recently Used」の略で、日本語では「最近最も使われていない」という意味です。LRUキャッシュは、最近アクセスされたデータを優先して保持し、古くなったデータを削除するアルゴリズムです。
キャッシュ戦略の比較
キャッシュにはさまざまな戦略があります:
- FIFO(First-In-First-Out): 最も古く追加されたデータから削除。単純ですが、必ずしも効率的ではありません。
- LFU(Least Frequently Used): 使用頻度が少ないデータを削除。頻繁に使われるデータに優先度をつけますが、管理が複雑です。
- MRU(Most Recently Used): 最近使われたデータを削除。特定のユースケースで有効です。
LRUは、最近アクセスされたデータが再びアクセスされる可能性が高いという前提に基づいており、Webアプリケーションやデータベースのキャッシュに最適です。
LRUキャッシュの仕組みをシンプルに解説
LRUキャッシュは、以下のルールに従ってデータを管理します:
- アクセス: データにアクセスすると、そのデータが「最近使用された」ものとして更新されます。
- 追加: 新しいデータが追加されると、キャッシュ内に空きがあればそのまま保存されます。
- 削除: キャッシュが満杯の場合、最も古く使われていないデータを削除して、新しいデータを追加します。
具体例
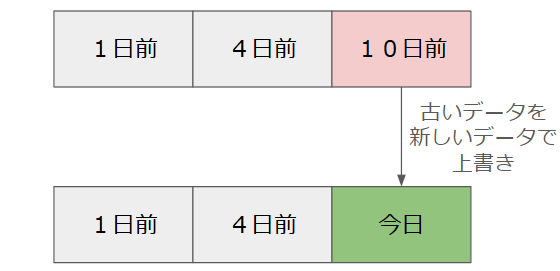
キャッシュサイズが3の場合を考えてみましょう:
アクセス: A→ キャッシュは[A]アクセス: B→ キャッシュは[A, B]アクセス: C→ キャッシュは[A, B, C]アクセス: D→ キャッシュは[B, C, D](Aは削除)アクセス: B→ キャッシュは[C, D, B](Bが更新される)アクセス: E→ キャッシュは[D, B, E](Cが削除)
一番古いデータは左、新しいデータは右にきます。
上の例で、古くなったデータが自動的に削除される様子が伺えます。
Pythonで簡単にLRUキャッシュを使ってみよう
Pythonには、標準ライブラリ functools に便利なデコレータ lru_cache が用意されています。これを使えば、簡単にLRUキャッシュを実装できます。
Pythonでの例
from functools import lru_cache
@lru_cache(maxsize=3)
def slow_function(n):
print(f"Computing {n}...")
return n * n
print(slow_function(1)) # 計算される
print(slow_function(2)) # 計算される
print(slow_function(3)) # 計算される
print(slow_function(1)) # キャッシュから取得
print(slow_function(4)) # 2が削除され、新たに4が追加
print(slow_function(2)) # 再計算される
出力結果
Computing 1...
1
Computing 2...
4
Computing 3...
9
1
Computing 4...
16
Computing 2...
4
ポイント:
maxsize=3でキャッシュの最大サイズが3に設定されています。slow_function(1)の2回目はキャッシュが利用され、計算されていません。
LRUキャッシュの実装方法
Pythonでは OrderedDict を使って簡単にLRUキャッシュを実装できます。以下はシンプルな実装例です。
LRUキャッシュの実装例
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity: int):
self.cache = OrderedDict()
self.capacity = capacity
def get(self, key: int) -> int:
if key not in self.cache:
return -1
self.cache.move_to_end(key)
return self.cache[key]
def put(self, key: int, value: int) -> None:
if key in self.cache:
self.cache.move_to_end(key)
self.cache[key] = value
if len(self.cache) > self.capacity:
self.cache.popitem(last=False)
# 使用例
cache = LRUCache(2)
cache.put(1, 1)
cache.put(2, 2)
print(cache.get(1)) # 1
cache.put(3, 3) # 2が削除される
print(cache.get(2)) # -1
LRUキャッシュのメリットとデメリット
メリット
- パフォーマンス向上: よく使われるデータをキャッシュすることで、アクセス速度が向上。
- メモリ効率: 古いデータを削除するため、メモリ使用量が抑えられる。
デメリット
- オーバーヘッド: キャッシュの管理には計算コストがかかる。
- 一貫性の問題: データが更新された場合、キャッシュされた古いデータが返されることがある。
- 適切なサイズ設定が必要: サイズが小さいとキャッシュミスが増え、大きすぎるとメモリを浪費する。
LRUキャッシュのユースケース
- Webアプリケーションのレスポンスキャッシュ: APIのレスポンスをキャッシュすることで、サーバーの負荷を軽減。
- ブラウザのキャッシュ: 画像やCSSファイルなどのリソースを効率的にキャッシュ。
- データベースクエリのキャッシュ: よく使われるクエリ結果をキャッシュして、データベースへのアクセスを最小限に。
まとめ
LRUキャッシュは、データのアクセスパターンを考慮した効率的なキャッシュアルゴリズムです。Pythonの標準ライブラリや自作の実装で簡単に利用できます。適切なサイズ設定やデータの一貫性に気をつけながら、アプリケーションのパフォーマンス向上にぜひ活用してください。
この記事が、LRUキャッシュの理解と実装の手助けとなれば幸いです。